High Availability
As more and more mission-critical applications move on the Internet, providing highly available services becomes increasingly important. One of the advantages of a clustered system is that it has hardware and software redundancy, because the cluster system consists of a number of independent nodes, and each node runs a copy of operating system and application software. High availability can be achieved by detecting node or daemon failures and reconfiguring the system appropriately, so that the workload can be taken over by the remaining nodes in the cluster.
In fact, high availability is a big field. An advanced highly available system may have a reliable group communication sub-system, membership management, quoram sub-systems, concurrent control sub-system and so on. There must be a lot of work to do. However, we can use some existing software packages to construct highly available LVS cluster systems now.
Working Principle
In general, there are service monitor daemons running on the load balancer to check server health periodically, as illustrated in the figure of LVS high availability. If there is no response for service access request or ICMP ECHO_REQUEST from a server in a specified time, the service monitor will consider the server is dead and remove it from the available server list at the load balancer, thus no new requests will be sent to this dead server. When the service monitor detects the dead server has recovered to work, the service monitor will add the server back to the available server list. Therefore, the load balancer can automatically mask the failure of service daemons or servers. Furthermore, administrators can also use system tools to add new servers to increase the system throughput or remove servers for system maintenance, without bringing down the whole system service.
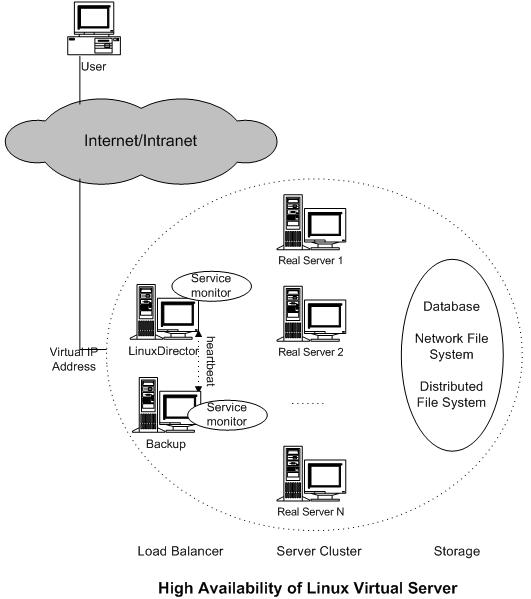
Now the load balancer might become a single failure point of the whole system. In order to prevent the whole system from being out of service because of the load balancer failure, we need setup a backup (or several backups) of the load balancer. Two heartbeat daemons run on the primary and the backup respectively, they heartbeat the message like "I'm alive" each other through serial lines and/or network interfaces periodically. When the heartbeat daemon of the backup cannot hear the heartbeat message from the primary in the specified time, it will take over the virtual IP address to provide the load-balancing service. When the failed load balancer comes back to work, there are two solutions, one is that it becomes the backup load balancer automatically, the other is the active load balancer releases the VIP address, and the recover one takes over the VIP address and becomes the primary load balancer again.
The primary load balancer has state of connections, i.e. which server the connection is forwarded to. If the backup load balancer takes over without those connections information, the clients have to send their requests again to access service. In order to make load balancer failover transparent to client applications, we implement connection synchronization in IPVS, the primary IPVS load balancer synchronizes connection information to the backup load balancers through UDP multicast. When the backup load balancer takes over after the primary one fails, the backup load balancer will have the state of most connections, so that almost all connections can continue to access the service through the backup load balancer.
The availability of database, network file system or distributed file system is not addressed here.
Working Examples
There are several software packages in conjuction with LVS to provide high availability of the whole system, such as Red Hat Piranha, Keepalived, UltraMonkey, heartbeat plus ldirectord, and heartbeat plus mon.
The following examples of building highly available LVS systems are only for reference.
- Using Piranha to build highly available LVS systems
- Using Keepalived to build highly available LVS systems
- Using UltraMonkey to build highly available LVS systems
- Using heartbeat+mon+coda to build highly available LVS systems
- Using heartbeat+ldirectord to build highly available LVS systems
There must be many other methods to build highly available LVS systems, please drop me a message if you have your methods.